

Joo-Young Kim (Google Scholar)
Laboratory :
https://castlab.kaist.ac.kr/
Teacher start-up company : HyperAccel Co., Ltd.(https://hyperaccel.ai)
Research LIST
Electrical Engineering
Development of a Novel AI Chip Specialized for Acceleration of Large Language Model InferenceTeacher start-up company : HyperAccel Co., Ltd.(https://hyperaccel.ai)
Research contents
Professor Joo-Young Kim's research team has developed the world's first LLM Processing Unit (LPU), a specialized semiconductor capable of accelerating the entire process of large language models (LLMs) such as GPT and Llama. The LPU maximizes the use of external DRAM memory bandwidth and integrates AI computation units specialized for LLMs, dramatically reducing token generation time. Additionally, by embedding its own networking technology, the LPU enables multi-chip scalability for hyperscale models. HyperAccel aims to develop highly efficient AI semiconductors specialized for LLM services and realize computing infrastructure to enable both businesses and individuals sustainably utilize LLMs.
Research results
Professor Kim's team has developed the world's first LLM Processing Unit (LPU), an acceleration semiconductor capable of performing the end-to-end process of the large AI models such as GPT. The designed accelerator is optimized to fully utilize the bandwidth of 32 memory channels of high-bandwidth memory (HBM) and integrates matrix computation units and vector computation units specialized for generative AI, significantly reducing the computation time for large AI models. Furthermore, a model parallelization technology that enables the efficient distribution of large AI models across multiple accelerators, as well as peer-to-peer (P2P) networking technology for data synchronization among accelerators, was also developed. The server platform composed of multiple LPUs achieved up to 5.6 times the performance, 4 times the power efficiency, and 8 times the cost efficiency compared to GPU servers for the publicly available GPT model. This work was selected for presentation at the top computer architecture conference, IEEE/ACM Microarchitecture (MICRO) in 2022. (Paper title: DFX: A Low-latency Multi-FPGA Appliance for Accelerating Transformer-based Text Generation). Following this, in subsequent research and development, the team won the Engineering Track Best Presentation Award at the top semiconductor design conference, IEEE/ACM Design Automation Conference (DAC) in 2023, receiving global recognition for its cutting-edge technology. (Presentation title: Latency Processing Unit (LPU) for Acceleration of Hyperscale AI Models).
 [Figure 1]
[Figure 1] This research is significant in that it proactively secures semiconductor technology capable of accelerating large language models (LLMs), which have recently become a hot topic in the system semiconductor field. Professor Kim founded HyperAccel in January 2023 to commercialize this technology. HyperAccel supports the development of generative AI technology and infrastructure through the acceleration of LLM inference, and is challenging innovations in the AI semiconductor field, including semiconductor chips, servers, and IP licensing. In the semiconductor chip business, the company offers memory bandwidth and AI-specialized logic optimized for generative AI computations through its self-developed AI processor, the LPU. The development has been already underway, and the chip is in the early production stage with major customers including companies providing generative AI services and data center operators. In the future, the company plans to expand its ASIC chip sales to companies offering on-device solutions such as in mobility and robotics. Currently, the chip is being manufactured using Samsung foundry’s 4nm process.
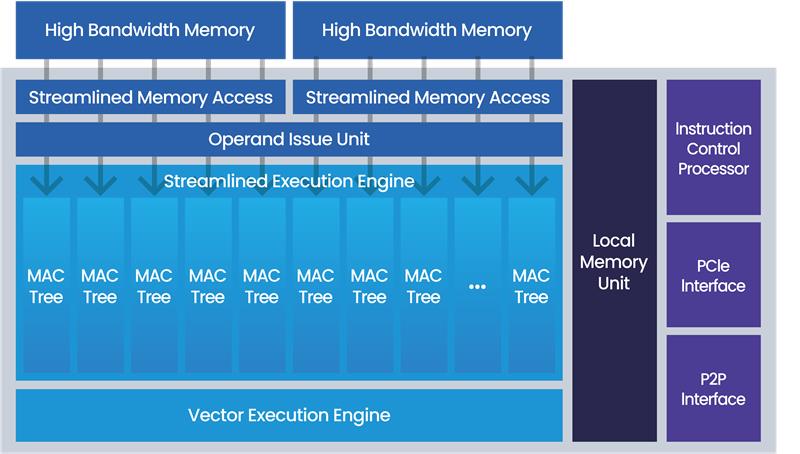 [Figure 2]
[Figure 2] In the server business, HyperAccel supports LLM inference acceleration and high-performance computation infrastructure through its AI-specialized Orion server, which was launched in November 2023. The company is currently supporting data center operations and on-premise server installations, with a goal of expanding to global data centers and providing cloud services.
 [Figure 3]
[Figure 3]